AWS Lambda с Java - быстро и недорого
AWS Lambda - популярная платформа для разработки serverless-функций, и как Java-разработчик мне нравится иметь возможность использовать эту платформу. Однако, есть некоторые важные моменты, о которых стоит помнить при работе с ней.
- Стоимость serverless-функций в AWS Lambda может быть высокой при использовании JVM.
- Холодные запуски AWS Lambda могут стать серьезной проблемой при использовании JVM.
- Увеличение эффективности AWS Lambda для каждого запроса (используя настройки RAM) может быть дорогостоящим, и при использовании JVM оно может быть не очень эффективным.
Это перевод статьи AWS Lambda with Java, a Fast and Low-Cost Approach, автор Amin Nasiri.
Две основные цели этой статьи заключаются в следующем:
- Изучить, как использовать сервисы AWS, например интеграцию DynamoDB с приложением на Quarkus, которое запущено как AWS Lambda функция.
- Добиться лучшей производительности на AWS Lambda при минимальных затратах.
Демо-приложение
Мы будем использовать как пример приложение на Java, разработанное на JDK 11 и Quarkus, которое представляет собой простую функцию AWS Lambda. Эта простая функция принимает имя фрукта в формате JSON и возвращает тип фрукта. Пример входных данных:
{
"name": "Apple"
}Типы фруктов для выходных данных:
- фрукты весеннего сезона (spring season fruit)
- фрукты летнего сезона (summer season fruit)
- фрукты осеннего сезона (fall season fruit)
- фрукты зимнего сезона (winter season fruit)
Схема приложения:
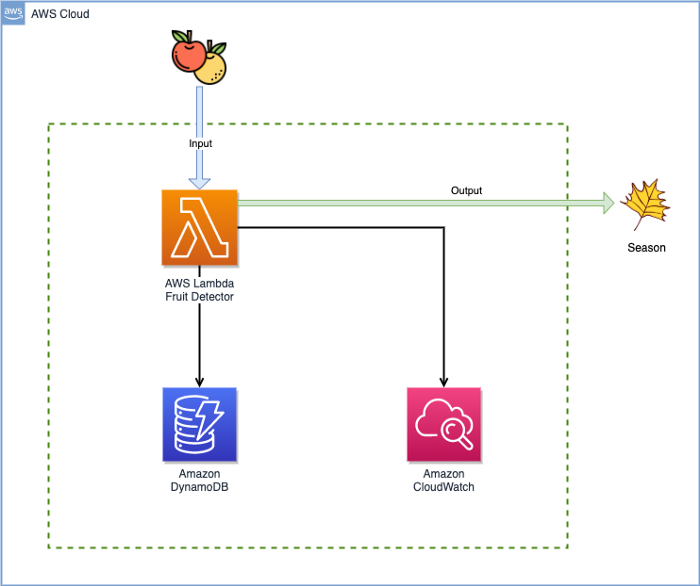
Воркфлоу взаимодействия юзера с системой
Это простое приложение на Java, которое извлекает запрошенную информацию о фруктах (тип фруктов) и возвращает её пользователю:
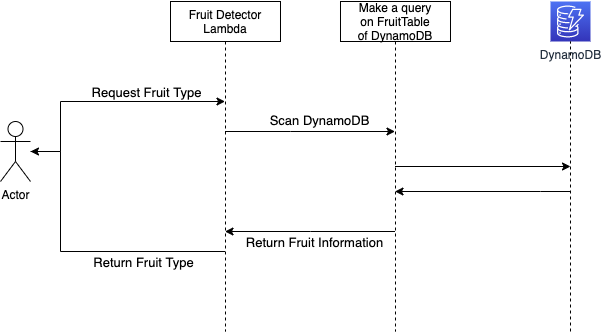
Создание Java-приложения на Quarkus
Quarkus предлагает четкое руководство, по которому можно сконфигурировать простой шаблон AWS Lambda функции. Этот шаблон проекта можно легко получить с помощью команды Maven:
mvn archetype:generate \
-DarchetypeGroupId=com.thinksky \
-DarchetypeArtifactId=aws-lambda-handler-qaurkus \
-DarchetypeVersion=2.1.3.FinalКоманда сгенерирует шаблон приложения с использованием AWS Java SDK. Quarkus имеет расширения для DynamoDB, S3, SNS, SQS и т.д., но я предпочитаю использовать AWS Java SDK v2, который предлагает неблокирующие функции. Итак, файл проекта pom.xml должен быть изменен в соответствии с этим руководством. В проекте есть зависимость Lambda в pom-файле
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-amazon-lambda</artifactId>
</dependency>Чтобы иметь возможность подключаться к DynamoDB нужно добавить необходимые зависимости:
<dependencies>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-amazon-dynamodb</artifactId>
</dependency>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-apache-httpclient</artifactId>
</dependency>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>apache-client</artifactId>
<exclusions>
<exclusion>
<artifactId>commons-logging</artifactId>
<groupId>commons-logging</groupId>
</exclusion>
</exclusions>
</dependency>
</dependencies>Также я буду использовать клиент apache, который можно добавить с помощью зависимости apache-client. В файле конфигурации (application.properties) нужно будет указать это:
quarkus.dynamodb.sync-client.type=apacheПреимущества использования Quarkus для разработки Java-приложения на AWS Lambda
Чаще всего Java-проект на AWS Lambda это довольно простое Java-приложение, однако используя Quarkus можно пользоваться внедрением зависимостей (Dependency Injection):
@ApplicationScoped
public class FruitService extends AbstractService {
@Inject
DynamoDbClient dynamoDB;
public List<Fruit> findAll() {
return dynamoDB.scanPaginator(scanRequest())
.items()
.stream()
.map(Fruit::from)
.collect(Collectors.toList());
}
public List<Fruit> add(Fruit fruit) {
dynamoDB.putItem(putRequest(fruit));
return findAll();
}
}DynamoDbClient это класс из AWS Java SDK v2, который Quarkus создаст и сделает доступным в своём контексте внедрения зависимостей. Класс FruitService является наследником абстрактного класса AbstractService, и этот абстрактный класс будет предоставлять базовые объекты, которые требуются для DynamoDbClient, например ScanRequest, PutItemRequest и т.д.
Механизм рефлексии (reflection) популярен в фреймворках Java, но он создаёт проблемы для нативного образа GraalVM (читайте больше информации - рефлексия в GraalVM), который мы будем собирать дальше. Но у Quarkus есть простое решение этой проблемы - аннотация к классам @RegisterForReflection. Это упрощает работу с классами и рефлексией в GraalVM.
@RegisterForReflection
public class Fruit {
private String name;
private Season type;
public Fruit() {}
public Fruit(String name, Season type) {
this.name = name;
this.type = type;
}
}Также Quarkus предлагает множество других интересных возможностей для работы с AWS Lambda, но я рассмотрю их в серии будущих статей.
Развертывание демо-приложения на AWS Lambda
Настало время развернуть наше приложение на AWS, и это будет относительно просто используя Maven и Quarkus. Однако перед развертыванием и запуском приложения требуется дополнительная настройка нашего окружения AWS. Процесс развертывания состоит из следующих этапов.
Создание таблицы Fruits_TBL в DynamoDB:
$ aws dynamodb create-table --table-name Fruits_TBL \
--attribute-definitions AttributeName=fruitName,AttributeType=S \
AttributeName=fruitType,AttributeType=S \
--key-schema AttributeName=fruitName,KeyType=HASH \
AttributeName=fruitType,KeyType=RANGE \
--provisioned-throughput ReadCapacityUnits=1,WriteCapacityUnits=1Заполнение этой таблицы тестовыми записями:
$ aws dynamodb put-item --table-name Fruits_TBL \
--item file://item.json \
--return-consumed-capacity TOTAL \
--return-item-collection-metrics SIZEВот содержимое файла item.json:
{
"fruitName": {
"S": "Apple"
},
"fruitType": {
"S": "Fall"
}
}Чтобы убедиться, что у нас есть элементы в таблице DynamoDB, запустим запрос:
$ aws dynamodb query \
--table-name Fruits_TBL \
--key-condition-expression "fruitName = :name" \
--expression-attribute-values '{":name":{"S":"Apple"}}'Определим роль в IAM, чтобы иметь доступ к DynamoDB, и назначим ее нашему приложению Lambda:
$ aws iam create-role --role-name fruits_service_role --assume-role-policy-document file://policy.jsonСодержимое файла policy.json:
{
"Version": "2012-10-17",
"Statement": {
"Effect": "Allow",
"Principal": {
"Service": [
"dynamodb.amazonaws.com",
"lambda.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
}Затем назначим этой роли разрешение на доступ к DynamoDB:
$ aws iam attach-role-policy --role-name fruits_service_role -- policy-arn "arn:aws:iam::aws:policy/AmazonDynamoDBFullAccess"Затем:
$ aws iam attach-role-policy --role-name fruits_service_role --policy-arn "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"Также может потребоваться следующее разрешение для роли:
$ aws iam attach-role-policy --role-name fruits_service_role --policy-arn "arn:aws:iam::aws:policy/AWSLambda_FullAccess"Наконец, платформа AWS готова к развёртыванию нашего приложения!
Чтобы продолжить процесс развертывания, нам нужно собрать наше приложение:
$ mvn clean installQuarkus позаботится о создании файла артефакта JAR и подготовит SAM-шаблон для AWS. Сейчас мы хотим запускать приложение в версии для JVM, и вот как это можно сделать. Добавьте определенную роль в Lambda, чтобы иметь правильный доступ:
Role: arn:aws:iam::{Your-Account-Number-On-AWS}:role/fruits_service_roleУвеличьте тайм-аут:
Timeout: 30Теперь шаблон SAM готов к развертыванию на AWS Lambda:
$ sam deploy -t target/sam.jvm.yaml -gЭта команда загрузит файл jar в формате zip в AWS и развернет его как функцию Lambda. Следующим шагом будет тестирование приложения.
Производительность демо-приложения на платформе AWS Lambda + JVM
Пришло время запустить развернутую лямбда-функцию, протестировать ее и посмотреть, насколько хорошо она работает:
$ aws lambda invoke response.txt --cli-binary-format raw-in-base64-out --function-name {:fruitApp} --payload file://payload.json --log-type Tail --query LogResult --output text | base64 --decodeМы можем выяснить FUNCTION_NAME, используя следующую команду:
$ aws lambda list-functions --query 'Functions[?starts_with(FunctionName, `fruitAppJVM`) == `true`].FunctionName'fruitAppJVM - это имя нашей Lambda-функции, которое я задал используя SAM CLI в процессе развертывания. Чтобы увидеть результаты вызова функции, мы можем обратиться к веб-консоли AWS.
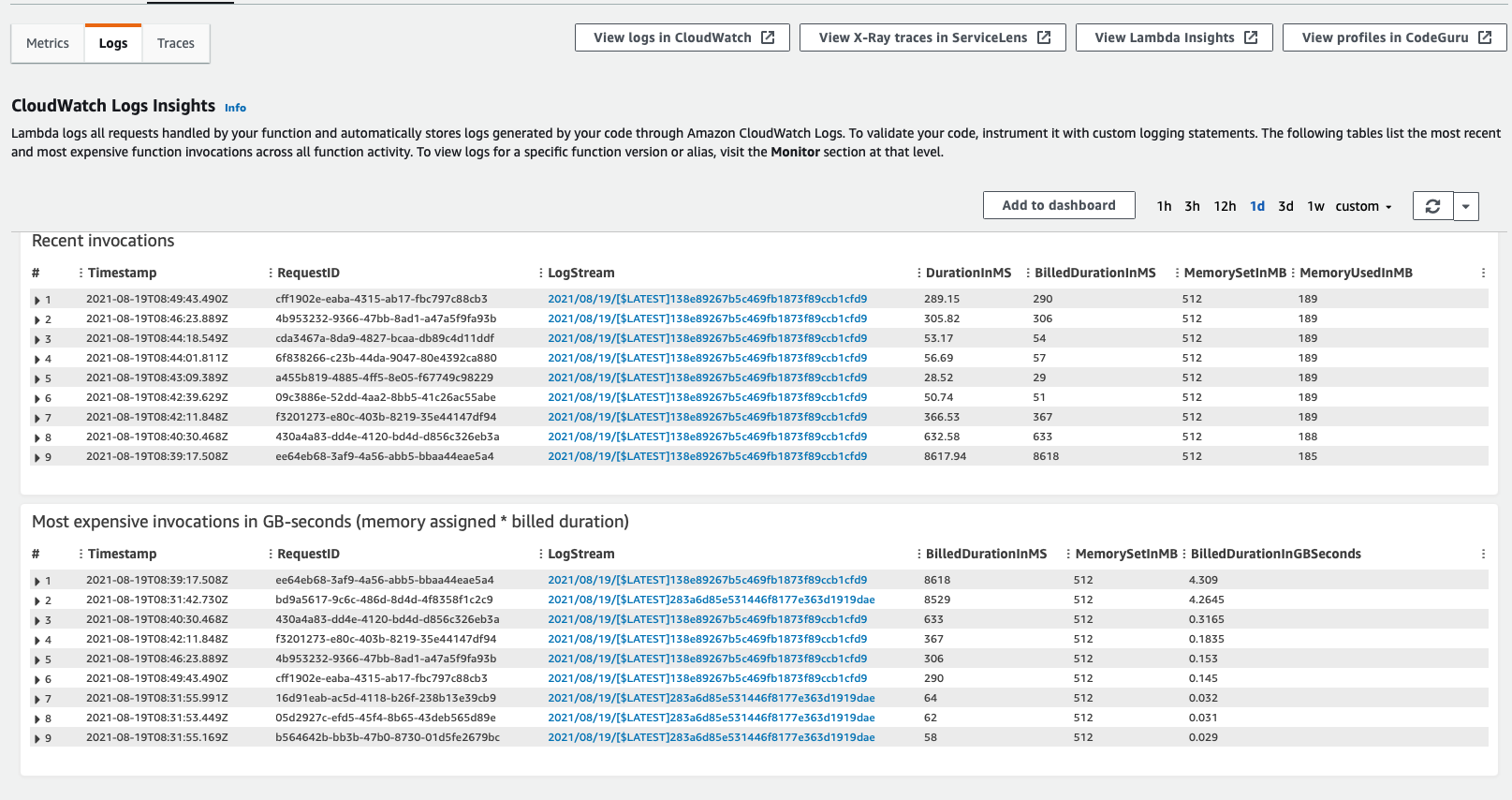
На изображении видно, насколько плоха может быть производительность для такого простого приложения из-за холодного запуска функции AWS Lambda.
Что такое холодный запуск AWS Lambda?
При запуске Lambda-функции она остается активной, пока ей активно пользуется, это значит, что контейнер с кодом функции остается запущенным и готовым принимать запросы. Однако, AWS выключает контейнер после некоторого периода бездействия (обычно очень короткого), и ваша функция станет неактивной (“холодной”). Холодный старт происходит, когда приходит запрос на простаивающую Lambda-функцию (контейнер которой был остановлен). После этого функция Lambda будет снова инициализирована, чтобы иметь возможность отвечать на запрос.
Также, при наличии доступных контейнеров вашей Lambda-функции происходит “теплый” запуск. Для получения дополнительной информации перейдите по этой ссылке.
Холодный запуск является основной причиной проблем с производительностью, поскольку каждый раз, когда происходит холодный запуск, AWS инициализирует наше Java-приложение, и, очевидно, это занимает много времени для каждого запроса.
Доступные решения для проблемы холодного запуска AWS Lambda
Есть два подхода к решению этой фундаментальной проблемы:
- Использование функциональности Provisioned Concurrency. Она не является предметом нашей статьи, подробности читайте в документации Predictable start-up times with Provisioned Concurrency.
- Повышение скорости инициализации и времени ответа приложения, что поднимает вопрос о том, как мы можем добиться лучшей производительности в нашем приложении Java. Решение - скомпилировать двоичный исполняемый файл из нашего Java-приложения и развернуть его на AWS Lambda с Oracle GraalVM.
Что такое GraalVM?
GraalVM - это высокопроизводительный дистрибутив JDK, разработанный для ускорения выполнения приложений, написанных на Java и других языках JVM, а также с поддержкой JavaScript, Ruby, Python и ряда других популярных языков. Native-Image - это ahead-of-time компилятор в составе GraalVM, который позволяет компилирорать Java код в бинарный исполняемый файл. Этот исполняемый файл включает все классы приложения, классы из его зависимостей и связанный код из JDK. Таким образом, скомпилированное так приложение не работает на JVM, а включает в себя необходимые компоненты, такие как управление памятью или планирование потоков из другой системы, называемой “Substrate VM”.
Создание бинарного исполняемого файла из Java-приложения
Во-первых, нам нужно установить GraalVM native-image, используя это руководство. Затем, установив GraalVM, мы можем преобразовать приложение Java в бинарный исполняемый файл с помощью GraalVM. Quarkus упрощает эту задачу и имеет плагин для Maven и Gradle, поэтому в типичном приложении на основе Quarkus у нас будет профиль, называемый native.
$ mvn clean install -PnativeMaven создаст бинарный исполняемый файл на основе используемой вами ОС. Если вы разрабатываете на Windows, этот файл можно будет запускать только на компьютерах с Windows, однако для AWS Lambda требуется исполняемый бинарный файл на для Linux. Для таких случаев Quarkus предоставляет параметр -Dquarkus.native.container-build=true.
$ mvn clean install -Pnative -Dquarkus.native.container-build=trueСреды выполнения AWS Lambda
AWS Lambda поддерживает несколько различных сред для запуска функций:
| Runtime | Amazon Linux | Amazon Linux 2 |
|---|---|---|
| Node.js | nodejs12.x | nodejs10.x |
| Python | python3.7 и 3.6 | python3.8 |
| Ruby | ruby2.5 | ruby2.7 |
| Java | java | java11, java8.al2 |
| Go | go1.x | provided.al2 |
| .NET | dotnetcore2.1 | dotnetcore3.1 |
| Custom | provided | provided.al2 |
Так мы ранее развернули Java-приложение на Lambda с помощью Java 11 (Corretto 11), и оно не показало хорошей производительности. Теперь же мы хотим попробовать два последних в таблице варианта чистой платформы Linux для Lambda-функций - provided и provided.al2. Стоит отметить, что provided будет использовать Amazon Linux, а provided.al2 будет использовать Amazon Linux 2, поэтому из-за долгосрочной поддержки версии 2 настоятельно рекомендуется использовать версию 2.
Развертывание бинарного исполняемого файла на AWS Lambda
Как мы видели, Quarkus создаст для нас два SAM-шаблона - один предназначен для Lambda-функции на JVM, а второй - для бинарного исполняемого файла. На этот раз мы должны использовать второй SAM-шаблон, это потребует небольших изменений в нём.
Перейти на AWS Linux V2:
Runtime: provided.al2Добавить определенную роль в Lambda, чтобы иметь надлежащий доступ:
Role: arn:aws:iam::{Your-Account-Number-On-AWS}:role/fruits_service_roleУвеличить тайм-аут:
Timeout: 30Окончательная версия SAM-шаблона будет иметь вид final.sam.native.yaml, теперь всё готово к развертыванию на AWS:
$ sam deploy -t target/sam.native.yaml -gЭта команда загрузит двоичный файл в формате zip в AWS и развернет его как функцию Lambda, точно так же, как версию JVM. Теперь мы можем перейти к самой интересной части - мониторингу производительности.
Производительность демо-приложения на основе AWS Lambda + Custom runtime
Пришло время запустить развернутую лямбда-функцию, протестировать ее и посмотреть, насколько хорошо она работает:
$ aws lambda invoke response.txt --cli-binary-format raw-in-base64-out --function-name {:fruitApp} --payload file://payload.json --log-type Tail --query LogResult --output text | base64 --decodeЧтобы узнать FUNCTION_NAME, мы можем воспользоваться следующей командой:
$ aws lambda list-functions --query 'Functions[?starts_with(FunctionName, `fruitAppNative`) == `true`].FunctionName'fruitAppNative - это имя Lambda-функции, которое я задал, используя SAM CLI в процессе развертывания.
Теперь мы можем открыть веб-консоль AWS, чтобы увидеть результаты вызова функции.
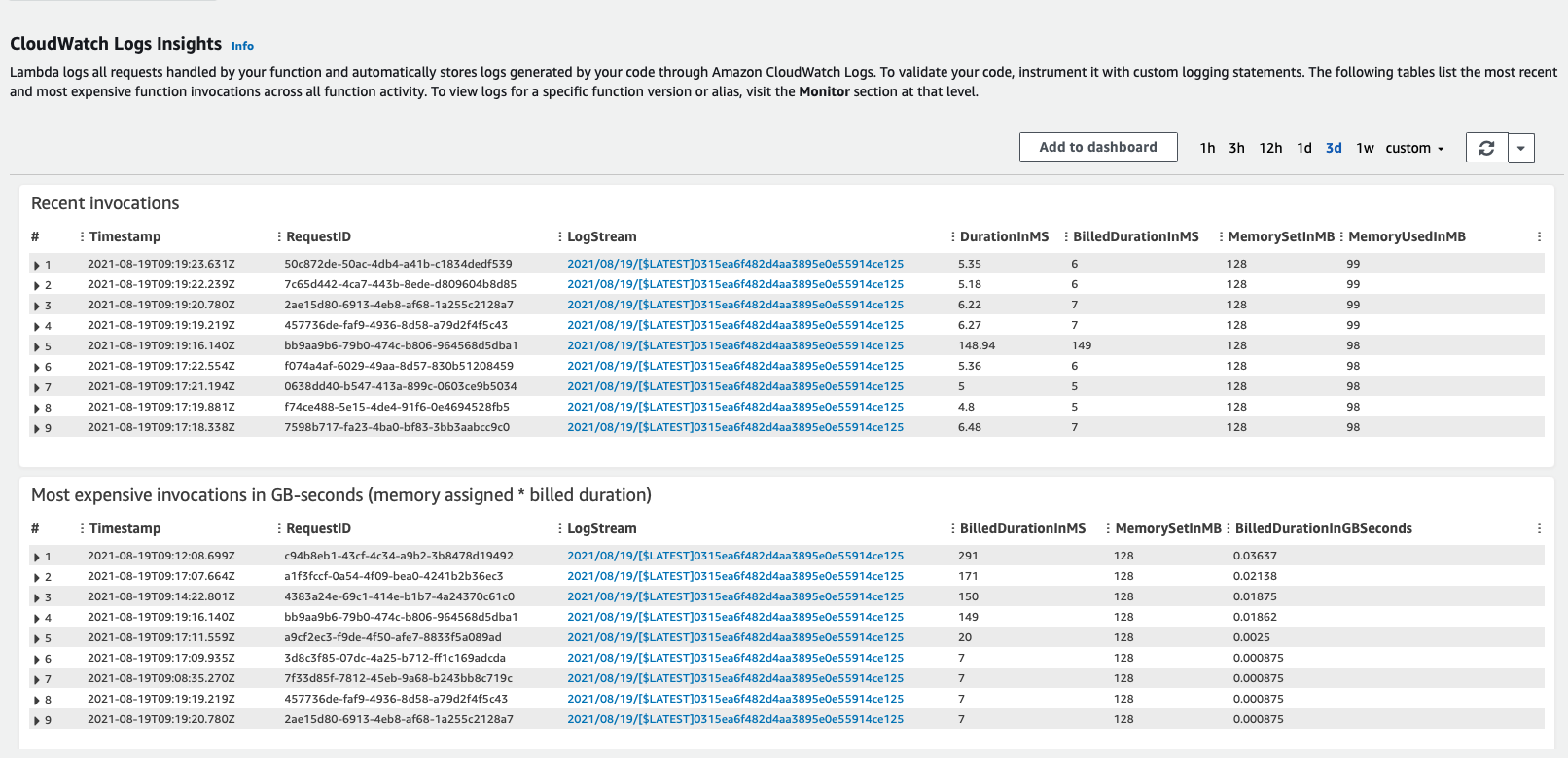
Сравниваем производительность Lambda-функций на JVM и Native Binary
Мы можем проанализировать и сравнить обе версии приложения на платформе AWS Lambda в двух категориях.
Время инициализации - это время, затраченное на первый вызов Lambda-функции. Это почти самая большая продолжительность вызова приложения на Lambda, потому что наше Java-приложение на этом этапе запускается с нуля.
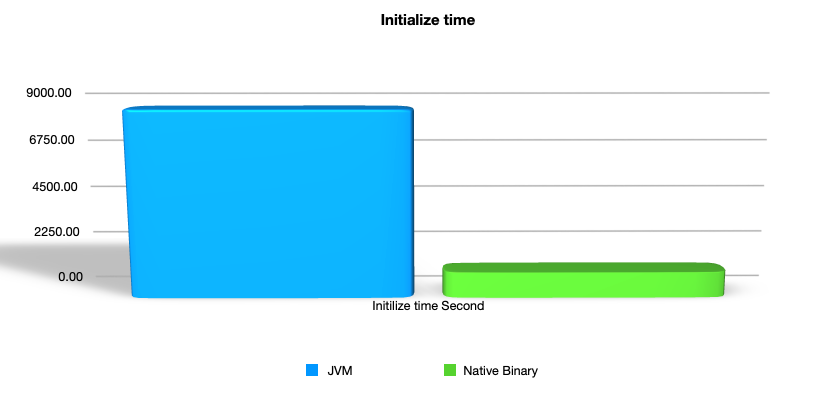
Между JVM и бинарной версией видна значительная разница - время инициализации нативной бинарной версии почти в восемь раз меньше, чем у версии JVM.
Время выполнения запроса - я вызвал лямбда-функцию девять раз после инициализированного шага, и вот результат производительности:
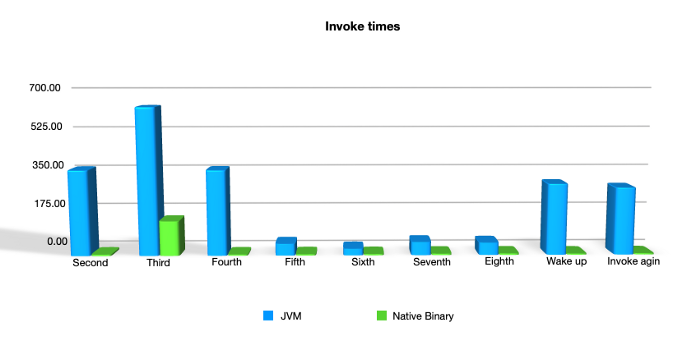
Судя по результату, существует значительная разница в производительности между версией JVM и версией, запущенной как бинарный файл.
Заключение
Quarkus помогает нам иметь четкий и структурированный код в Java-приложении, предоставляя некоторые полезные функции, такие как внедрение зависимостей. Кроме того, он помогает преобразовывать наше Java-приложение в нативный бинарный файл с помощью GraalVM.
Версия бинарного исполняемого файла имеет значительно лучшую производительность по сравнению с версией JVM:
- версия бинарного файла использует всего 128МБ оперативной памяти, тогда как версия JVM использует 512МБ, что приводит к экономии значительного количества ресурсов на AWS Lambda;
- версия бинарного файла показывает лучшее время выполнения запросов чем версия JVM, что означает большую экономию времени на AWS Lambda.
В итоге, за счет экономии ресурсов и времени подход с бинарным исполняемым файлом оказался более выгодным вариантом с точки зрения производительности и финансов.